Sections, séquences. Chasse fixe et hiérarchisation mobile pour le code informatique
Les interfaces de programmation retracent un lien visuel direct avec les premiers affichages de textes à l’écran. La contrainte du pixel s’effaçant de plus en plus avec les avancées technologiques, les polices matricielles ont disparu des écrans et la chasse constante n’est plus une contrainte, mais semble survivre en teintant le texte de programmation de la même régularité.
Placer des signes typographiques sur une grille réglée n’est pourtant pas idéale pour le confort de lecture du fait de la distorsion qu’elle entraîne sur les formes. Là où un mode de lecture habituel se fait par une évaluation de la silhouette du mot avant même celle de ses caractères propres, une homogénéisation des espaces influe directement sur cette reconnaissance et ainsi sur le rythme de lecture.
Il semble y avoir une réelle motivation à l’utilisation de la monochasse dans le code. Ce qui résultait d’une contrainte technique au début de l’informatique est devenu un choix pratique.
L’écriture du code informatique possède la particularité de s’adresser à deux lecteurs. Le premier est la machine réceptrice des instructions qui ingérera le texte et en reconnaîtra le contenu. La seconde lecture sera humaine, elle pourra concerner des individus uniques ou multiples que ce soit au moment même de la rédaction du texte ou dans un besoin ultérieur de lecture.
Le procédé de déchiffrage de la machine se caractérise par une intégration successive de signes. Le groupe/le mot n’est ainsi reconnu comme tel qu’après l’identification de chacun de ses signes. La machine réceptrice est en cela indifférente à l’image du texte. Ainsi, les choix visuels qui conditionnent la représentation du code et qui ont pour but d’en faciliter la lecture s’adressent exclusivement au lecteur humain.
Le choix d’un caractère monochasse pour l’écriture du code semble alors être une réponse à ce mode de déchiffrage particulier et apparaît comme une volonté de se rapprocher du mode de lecture de la machine. La ligne de code étant assimilée à une somme d’unités, la chasse constante autorise une équivalence spatiale de chaque signe d’écriture. Chaque lettre, chaque symbole gagne ainsi la même importance spatiale, égrenant le mot d’une manière semblable à celle de la machine lors de son déchiffrement. Ce procédé cherche en cela à forcer l’œil à s’arrêter sur chacun des signes qui composent le texte dans un but de détection de la moindre coquille qui pourrait être fatale à la bonne exécution du programme.
La lecture du code est d’autant plus particulière que le déchiffrage du texte ne s’effectue pas de manière linéaire, du début à la fin du texte, ligne après ligne. C’est davantage par sauts de l’œil que celle-ci fonctionne, de passage en passage, de ligne en ligne, en pouvant effectuer des aller-retours, des relectures multiples d’un même passage. La monochasse, en plaçant le texte sur une grille homogène va alors favoriser les déambulations de l’œil mais pourra du même fait l’amputer de points d’accroche sur lesquels s’appuyer. Pour pallier cela, l’utilisation de signes non-alphabétiques, plus importante que dans un texte de langue naturelle, pourront permettre de recréer des ensembles au sein du texte. C’est par exemple le cas des parenthèses, accolades ou crochets utilisés dans bon nombre de langages de programmation.
Il apparaît alors que la réaffirmation d’ensembles au sein de cette grille monochasse uniforme soit l’un des enjeux principaux auxquels se doit de répondre la mise en forme de l’image du texte. Cela passe inévitablement par une gestion de l’espace entourant les signes d’écriture, des blancs, qu’ils soient de l’ordre de l’interlignage — qui permettra de retrouver une horizontalité de la lecture — ou de l’exploitation des espaces intermots, ceux-ci n’étant pas pris en compte par la machine dans le cas d’un certain nombre de langages de programmation.
C’est pourquoi il est d’usage dans l’écriture du code d’agrémenter le texte de tabulations en début de ligne qui permettront au lecteur humain de faire émerger de son texte les possibles liens de subordination et par la même occasion de créer de nouveaux points d’accroche à sa lecture. Cette pratique est en partie responsable de la persistance de caractères monochasse dans l’écriture du code. En effet, ces derniers facilitant les alignements verticaux, le programmeur peut alors tabuler les différentes lignes de son texte par la simple frappe d’espaces successives et ainsi faire émerger l’arborescence du texte. La chasse constante autorise une mise en forme du texte simultanée à son écriture. Il existe un autre procédé appelé « coloration syntaxique » qui semble aujourd’hui inhérent au façonnage de l’image du texte de programmation. Celui-ci, désormais proposé par défaut dans les interfaces de programmation, a pour but de repérer les différents types d’attributs d’un langage en leur associant une couleur propre. Il vise ainsi à créer de nouveaux points de repère qui accrocheront l’œil et permettront au lecteur de faciliter le ciblage dans sa lecture.
Le projet de caractère typographique développé autour de l’écriture du code cherche à privilégier l’appréhension du groupe-mot, cette volonté de parceller le texte semblant d’autant plus nécessaire qu’elle convient à des langages de programmation fonctionnant par balises. Ce projet cherche ainsi à proposer un système discriminant qui se conformerait au mode de lecture particulier du code informatique tout en dotant le texte d’une hiérarchisation plus spécifique et mobile que la coloration syntaxique. 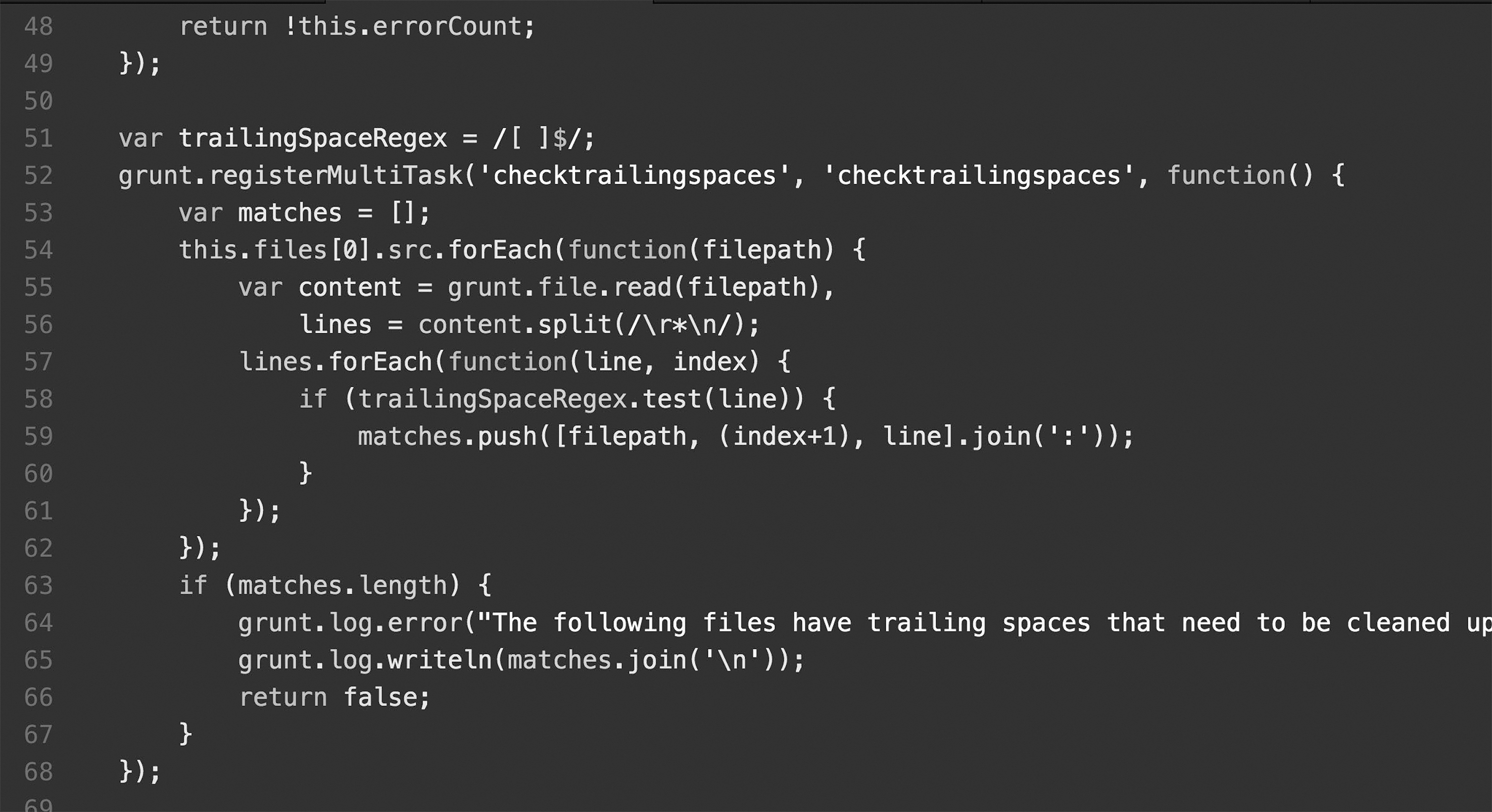 Hiérarchie telle qu’elle est d’usage avec les tabulations et coloration syntaxique.
Hiérarchie telle qu’elle est d’usage avec les tabulations et coloration syntaxique. Principe mis en place d’une hiérarchie par la silhouette typographique.
Principe mis en place d’une hiérarchie par la silhouette typographique.
Il n’existe pas de standards en soi pour les modalités d’affichage du code, autres que ceux proposés par les interfaces de programmation. Au-delà de cela, le choix de la police, sa taille d’affichage, sa valeur d'interlignage, le choix des couleurs de fond et de coloration syntaxique pourront être modifiés selon un confort de lecture/écriture propre à chaque programmeur.
Des projets de caractère à l’image de la police Input de David Jonathan Ross cherchent à optimiser cette personnalisation en proposant un caractère de code paramétrable par l’ajout ou non d’empattements, l’utilisation ou non d’une chasse constante, le choix du corps d’affichage, de la graisse, et de la largeur de chasse.
Cette recherche proposant une nouvelle hypothèse de visualisation du code, c’est dans cette volonté manifeste de faire porter la hiérarchisation par la typographie seule que la coloration du texte a été écartée.
Le système s’articule ainsi autour d’un caractère dont les variantes sont basées sur les principes discriminants usuels de l’écriture numérique : soulignement, négatif, gras…  Ensemble des variantes du caractère typographique conçu pour le code. Ces variantes, par la simplicité du vocabulaire formel mis en place doivent permettre une adaptation aux besoins de distinction et de hiérarchisation de divers langages de programmation.
Ensemble des variantes du caractère typographique conçu pour le code. Ces variantes, par la simplicité du vocabulaire formel mis en place doivent permettre une adaptation aux besoins de distinction et de hiérarchisation de divers langages de programmation.
Mais au-delà de cette mobilité, le système a vocation à pouvoir se conformer à ce que l’utilisateur choisit de voir. Il n’est pas question ici de confort de lecture comme l’entend le projet Input mais de confort de hiérarchisation dans le sens où l’utilisateur peut être apte à choisir les types de contenus qu’il souhaite voir mis en valeur et selon quelle hiérarchie, cela de manière mobile et interchangeable.
La hiérarchisation telle qu’elle aurait put être envisagée pour un autre contenu complexe comme, par exemple, une définition de dictionnaire, n’est ici pas limitée du fait du support numérique. La forme peut ici varier au gré des besoins d’utilisation, l’image du texte pouvant être d’autant plus éphémère qu’elle ne sera pas ingérée par son ultime lecteur, la machine. Le système cherche à exploiter la malléabilité possible de l’image du texte de programmation, celle-ci pouvant être modifiée, altérée dans le seul but de faciliter son écriture et sa lecture par le programmeur. Le texte n’étant qu’une image, l’utilisateur peut ainsi choisir ce qu’il décide de voir affiché ou non,  Le système permet de graduer les types de contenus que l’utilisateur souhaite mettre en valeur. Ici, la répartition stylistique fait émerger la structure du texte en html. ainsi, des fragments du texte peuvent disparaître pour ajouter de la clarté à sa structure.
Le système permet de graduer les types de contenus que l’utilisateur souhaite mettre en valeur. Ici, la répartition stylistique fait émerger la structure du texte en html. ainsi, des fragments du texte peuvent disparaître pour ajouter de la clarté à sa structure. 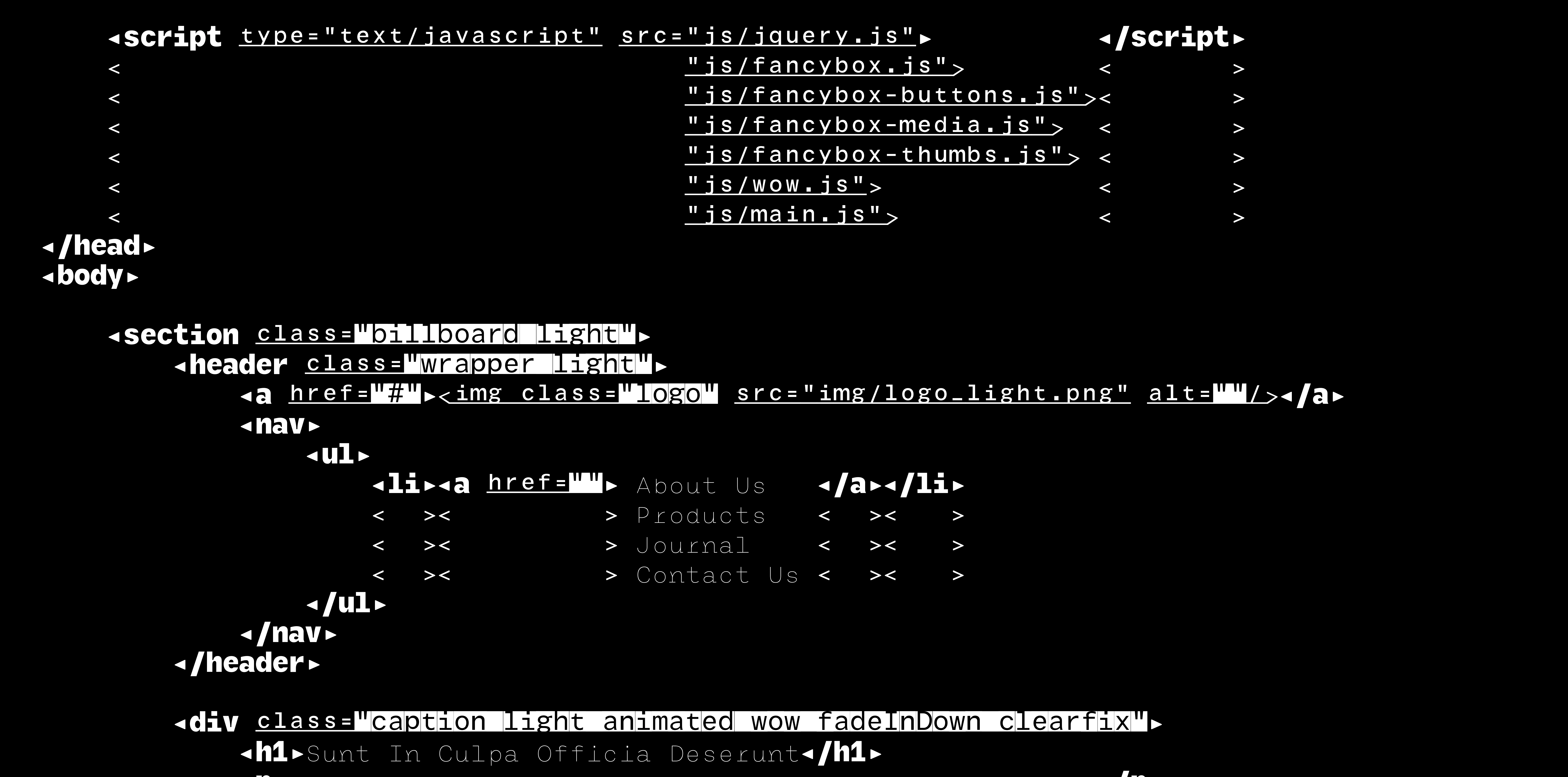 De manière à éviter les répétitions, les contenus présents sur plusieurs lignes consécutives disparaissent pour laisser visibles ceux qui différent. Les éléments structurels (crochets) restent et changent de forme pour signaler le texte non-affiché. L’intervention sur l’image du code ne se limitant plus à une hiérarchisation typographique, le système peut alors accueillir un retour de la couleur, qui, libérée de son objectif premier de distinction peut gagner à revenir dans un objectif nouveau d’ergonomie.
De manière à éviter les répétitions, les contenus présents sur plusieurs lignes consécutives disparaissent pour laisser visibles ceux qui différent. Les éléments structurels (crochets) restent et changent de forme pour signaler le texte non-affiché. L’intervention sur l’image du code ne se limitant plus à une hiérarchisation typographique, le système peut alors accueillir un retour de la couleur, qui, libérée de son objectif premier de distinction peut gagner à revenir dans un objectif nouveau d’ergonomie. 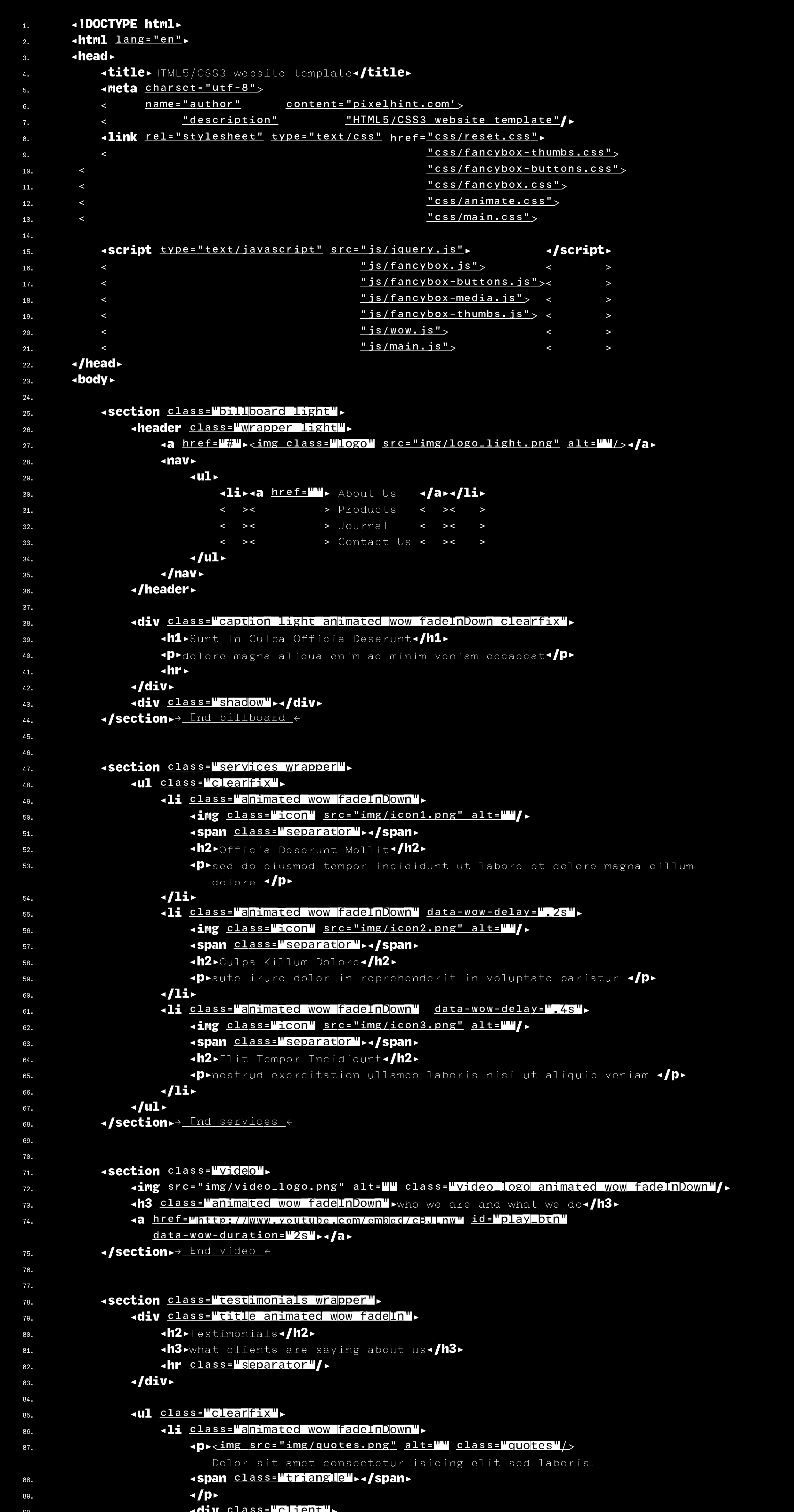 Exemple de page de code utilisant la famille de caractères typographiques créée.
Exemple de page de code utilisant la famille de caractères typographiques créée.